DeepSeek-V3 Release: New Open-Source MoE Model
On December 26, 2024, DeepSeek officially released a new open-source large language model DeepSeek-V3, a Mixture-of-Experts (MoE) model with 671 billion parameters. Despite being open-source, DeepSeek-V3 shows performance comparable to top models like GPT-4 and Claude 3.5 Sonnet.
In this blog, we will dive into the features of DeepSeek-V3, its benchmarks, and compare it to its predecessor, DeepSeek-V2.

| Specs | Description |
|---|---|
| Provider | DeepSeek AI. Also available through major inference platforms. |
| Model Size | 671 billion total parameters 37 billion activated parameters per token |
| Context Window | 128,000 tokens |
| Speed | ~60 tokens / second (3x faster than V2) |
| Latency (TTFT) | ~0.76 seconds / token |
| Input Cost | $0.27 / million tokens ($0.07/million tokens with cache hits) |
| Output Cost | $1.10 / million tokens |
| Recommended For | Coding, mathematical reasoning, educational tools, language translation. Use cases that require fast inference or a cost-effective solution. |
What is DeepSeek-V3?
DeepSeek-V3 is the most advanced open-source Mixture-of-Experts (MoE) Large Language Model from DeepSeek as of December 2024. A key feature of MoE models is selective activation, which allows DeepSeek-V3 to process information quickly while maintaining the benefits of a very large model.
The first version DeepSeek-V1 laid the groundwork for the Mixture-of-Experts (MoE) architecture, allowing for multiple specialized models (or "experts") to collaborate on tasks. Building on the successes of V1, DeepSeek-V2 introduced enhancements in the model architecture and training efficiency.
"Best Value in the Market"
V3 sets a new benchmark for open-source models with exceptional performance and surprising affordability. This advanced model positions itself as the best value in the market with comparable performance to closed-source giants like OpenAI's GPT-4 and Anthropic's Claude 3.5 Sonnet.

DeepSeek V3 is one of the most cost-effective models in the market, with a price of $0.27 per million input tokens and $1.10 per million output tokens, compared to $3.00/million input tokens and $15.00/million output tokens for Claude 3.5 Sonnet.
In terms of cost, developers now compare DeepSeek V3 with the latest models like Llama 3.3. Here's a breakdown of the average cost of each model:
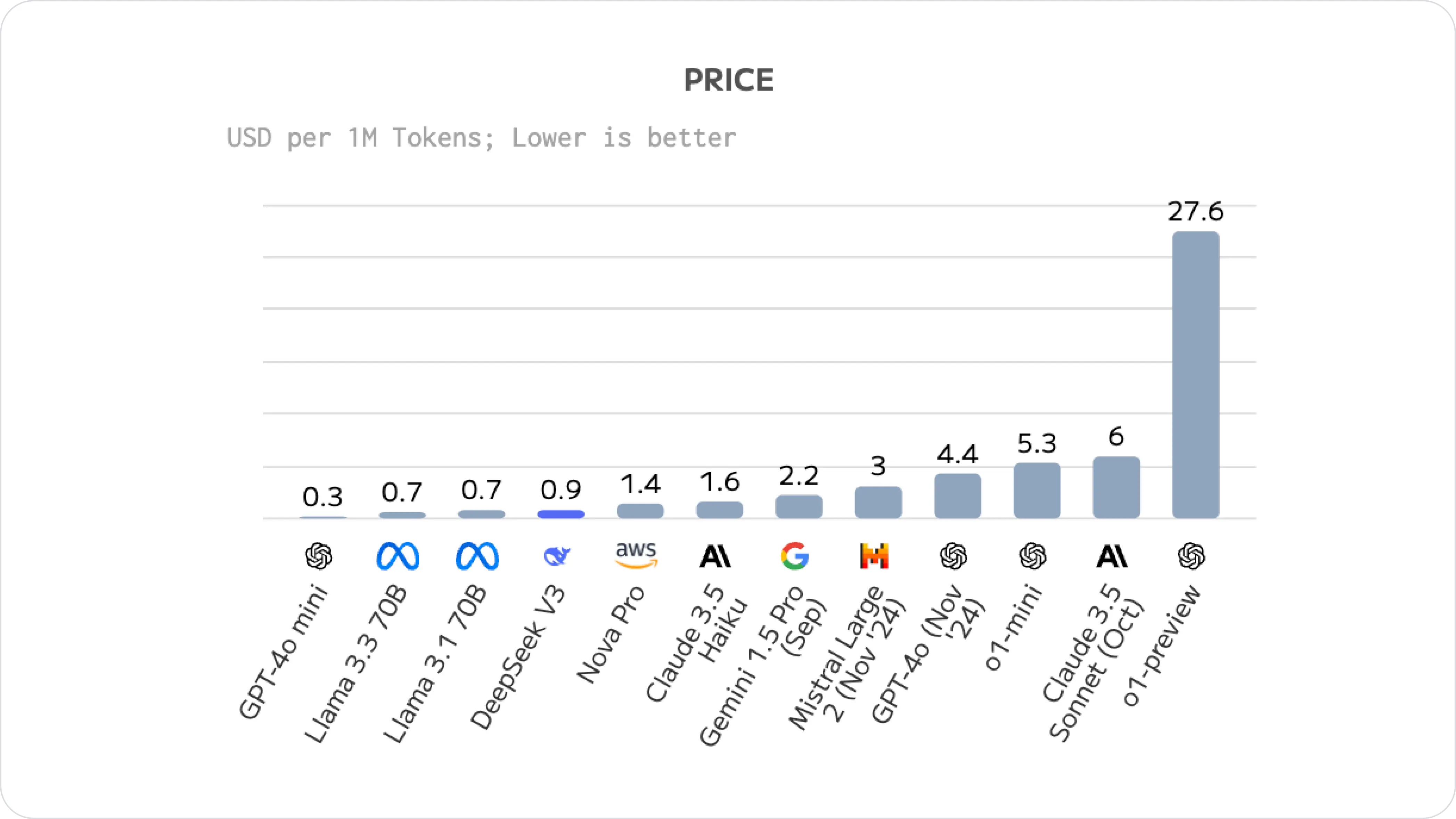
Developer’s Take on DeepSeek-V3
“The model's intelligence along with how cheap it is basically lets you build AI into whatever you want without worrying about the cost.“
How does V3 compare with V2?
At approximately 60 tokens per second, DeepSeek-V3 has a 3x faster response rate compared to DeepSeek-V2, ideal for applications that need fast analysis, real-time language processing, or high-throughput data handling.
| DeepSeek-V3 | DeepSeek-V2 | |
|---|---|---|
| Total Parameters | 671 billion | 236 billion |
| Activated Parameters per Token | 37 billion | 21 billion |
| Context Length | Extends context length support in two stages, increasing from 32,000 tokens to 128,000 tokens. | 128,000 tokens |
| Architectural Features | Retains MLA and DeepSeekMoE, and introduces a router for selective network activation. | Utilizes Multi-head Latent Attention (MLA) and DeepSeekMoE for efficient inference and training. |
| Benchmark Performance | Excels in coding tasks and mathematics assessments, competitive with GPT-4 in code generation benchmarks. | Scored 80 on the HumanEval benchmark, showcasing robust coding capabilities. |
| Generation Throughput | Processes 60 tokens/second (3x faster than DeepSeek-V2) | Maximum generation throughput 5.76x that of DeepSeek 67B, with 93.3% KV cache usage reduction. |
| Pre Training Dataset | Trained on 14.8 trillion tokens, enhancing versatility and domain performance. | Trained on 8.1 trillion tokens, utilizing SFT and RL for alignment with human preferences. |
Reference: DeepSeek-V3 Technical Report, DeepSeek-V2 Technical Report
DeepSeek V3 Benchmarks
DeepSeek V3 consistently outperforms its predecessors and most competitors, particularly excelling in mathematical reasoning (MATH-500), coding tasks (Codeforces, LiveCodeBench), and Chinese evaluations (C-Eval, C-SimpleQA), demonstrating its scalability and advanced capabilities.
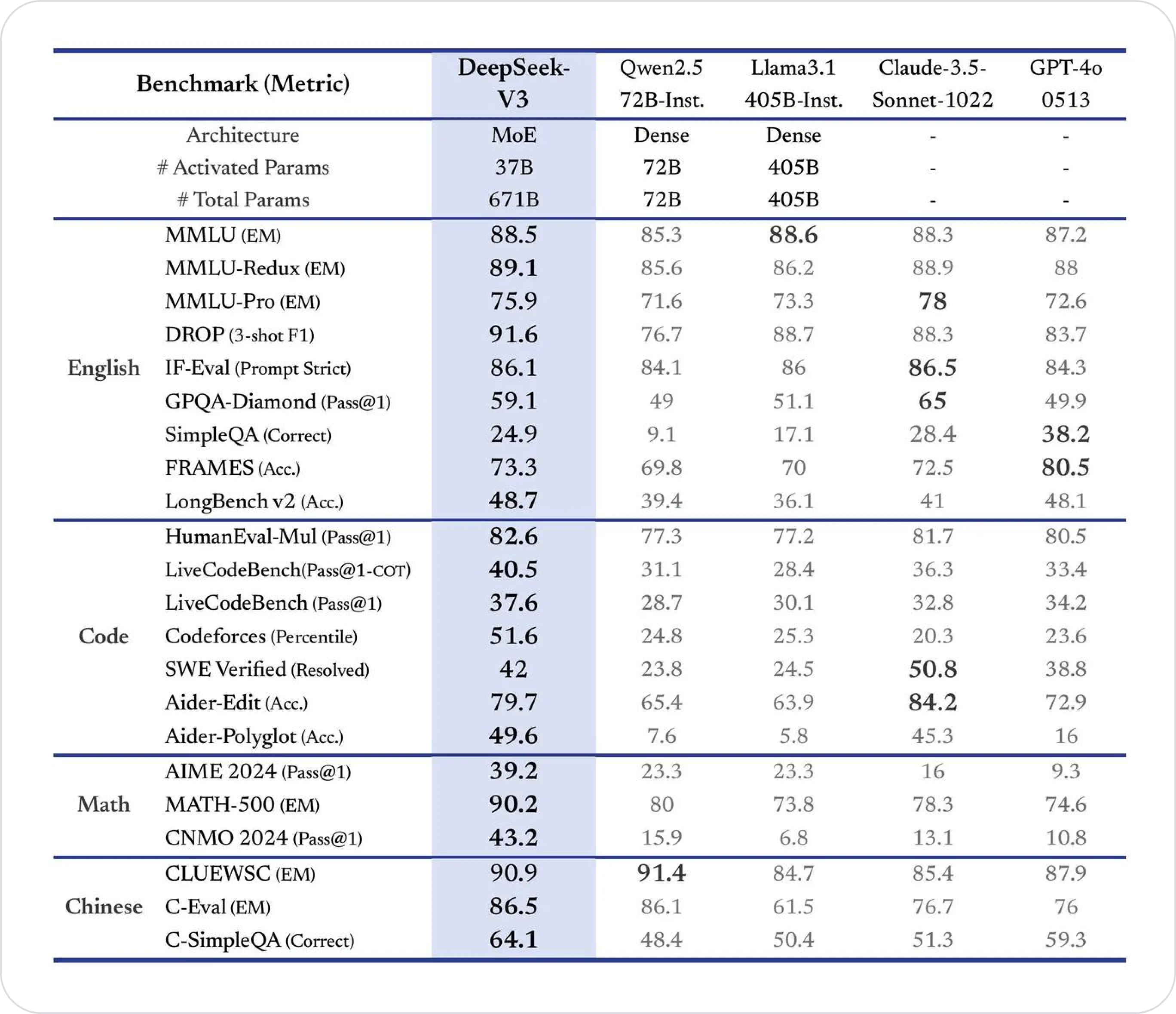
When comparing DeepSeek V3, it's on equal footing with Claude-3.5-Sonnet and OpenAI o1, but it does lack the context window significantly. If your task is short, it's wonderful.
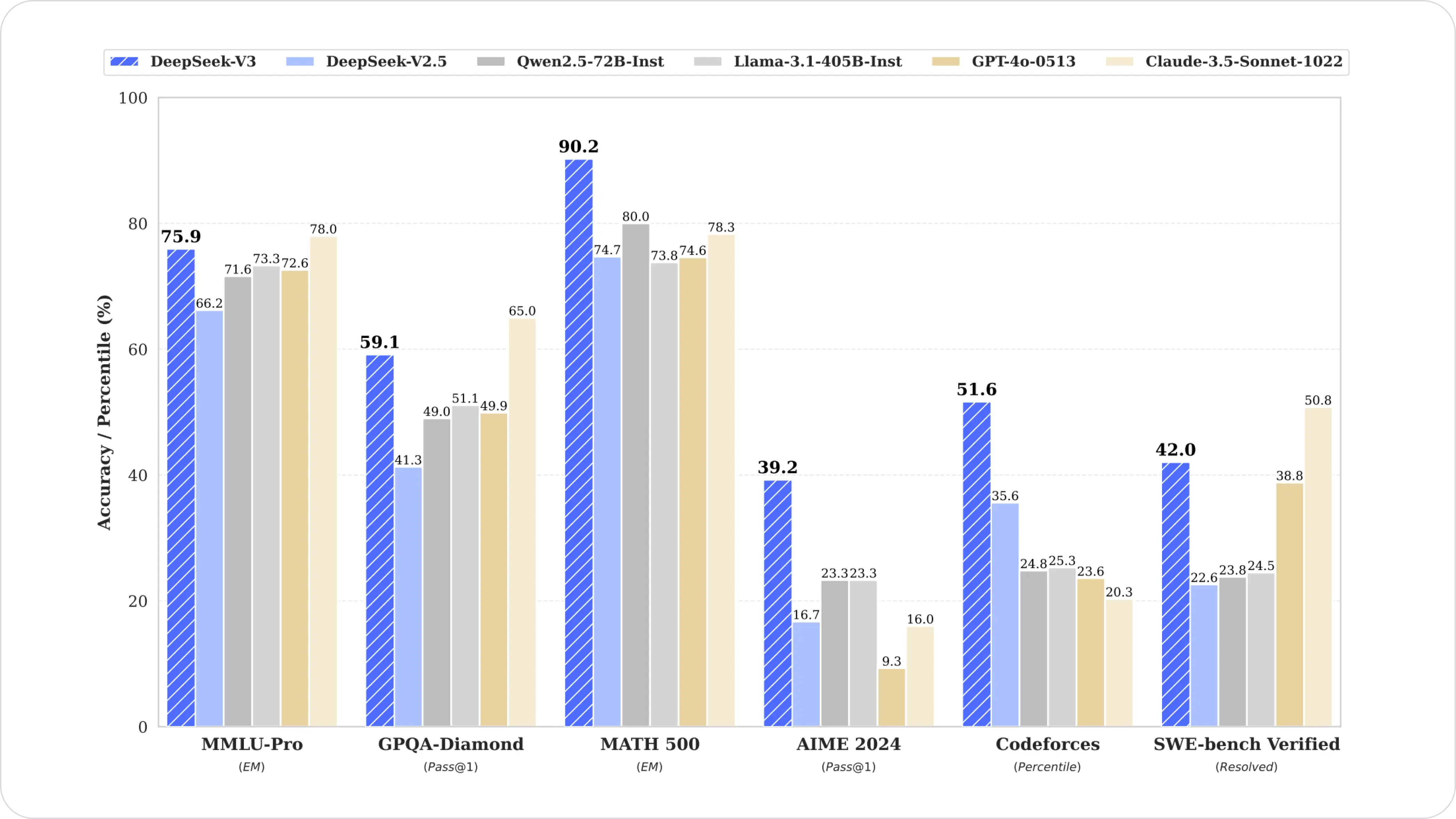
Image Source: Benchmark performance of DeepSeek-V3 and its counterparts
Education and Reasoning
DeepSeek-V3 achieved notable results in MMLU (Massive Multitask Language Understanding) with a top score of 88.5, surpassing all open-source models. It also performed exceptionally well in MMLU-Pro, securing a score of 75.9, affirming its ability to handle complex, multitasking challenges. Its performance on GPQA (General Purpose Question Answering) reflected strong reasoning and factual knowledge, with a score of 59.1.
Mathematics
DeepSeek V3 demonstrated exceptional mathematical reasoning by scoring 90.2 in the MATH-500 test. This performance surpassed other models, including closed-source competitors, reinforcing its capability to handle computationally demanding tasks.
Code Generation
DeepSeek-V3 showcased its prowess in competitive programming, scoring in the 51.6 percentile on Codeforces and achieving a resolution rate of 42.0 on SWE-Bench Verified. It also emerged as the top-performing open-source model on LiveCodeBench, cementing its position as a leader in software development and programming challenges.
How to Access DeepSeek V3
| Method | Description |
|---|---|
| OpenRouter (Some developers recommend) | Access DeepSeek V3 on OpenRouter by purchasing credits. To monitor your AI app, developers use OpenRouter with Helicone to track usage and cost. |
| Chat | Access DeepSeek V3 directly via chat on the official website. |
| API Access | OpenAI-compatible API available through the DeepSeek Platform. Invoke DeepSeek-V3 by specifying model=deepseek-chat. You can also use other endpoint providers. |
| Local Deployment | Clone the official repository to access DeepSeek V3, including pre-trained model checkpoints, documentation, and code examples. |
How to Monitor DeepSeek V3 Applications
Integrate your DeepSeek application with Helicone to get powerful LLM analytics and observability. Follow these steps:
# Set DeepSeek + Helicone API Keys as environment variables
HELICONE_API_KEY=<your API key>
DEEPSEEK_API_KEY=<your API key>
# Update the base URL
https://api.deepseek.ai/v1/chat/completions # old
https://deepseek.helicone.ai/v1/chat/completions # new
# Add Auth headers
Helicone-Auth: `Bearer ${HELICONE_API_KEY}`
Authorization: `Bearer ${DEEPSEEK_API_KEY}`
Should you use DeepSeek-V3?
Advantages
- DeepSeek V3 outperforms leading models like Llama 3.1 and GPT-4 in coding benchmarks, offering a cost-effective alternative.
- As an open-source model, DeepSeek-V3 is versatile and very customizable. Developers can integrate it into diverse applications. Use cases include code completion and mathematical reasoning.
Limitations
- DeepSeek-V3 has a strong performance if the smaller 64k context window is not a concern for you (according to DeepSeek’s official api). You can also deploy it yourself or another endpoint like these providers, which may be able to provide a 128k context window.
- The model occasionally generates responses that deviate from user expectations or established interpretations, which indicates room for improvement in reasoning.
- Some developers noticed that DeepSeek V3 occasionally generates "doom loops", where similar responses are produced consecutively/repeatedly. However, this may be improved with effective prompt engineering.
Bottom Line
DeepSeek V3 is a game-changer in the open-source LLM landscape, delivering performance that rivals proprietary heavyweights like GPT-4 and Claude 3.5 across critical benchmarks. As with any model choice, there are tradeoffs to consider for your specific implementation.
For teams prioritizing both cost-efficiency and local deployment, DeepSeek stands out in the current open-source ecosystem. Its robust reasoning capabilities and competitive inference costs make it particularly compelling for production environments. The model's architecture also sets an interesting precedent for future open-source developments in the space.
You might also be interested in:
-
Top 10 Inference Platforms in 2025 to Access V3
-
Building an LLM Stack
-
5 Powerful Techniques to Slash Your LLM Cost
Questions or feedback?
Are the information out of date? Please raise an issue or contact us, we'd love to hear from you!